The Two Questions MEP Firms Should Ask Before Buying Any AI Tool
Every MEP firm is being pitched AI right now. Plugin vendors, consultancies, productivity tools, even the firms across the street are claiming they've found the AI workflow that's going to change everything. Most of those pitches fall apart under two simple questions. If a vendor can't answer both of them clearly, the tool isn't ready, and neither is the firm that buys it.
The first question is about where the data goes. AI tools work by sending some piece of your work to a model, and the model sends an answer back. The interesting question is what happens to the work in between. The cheap, fast, and dangerous version of this is when the vendor's model provider uses every prompt that passes through it to improve the model itself. That means a detail from your project, a specification from your spec book, an email from a client, or a CAD note from a junior engineer becomes training data for a model that competitors, vendors, and the general public will eventually query. Most consumer AI products work this way by default. Most enterprise tools claim they don't, but the only way to verify it is to read the actual contract and the underlying model provider's data-handling commitments. If the vendor is opaque about this, or routes through a free-tier API, the answer is almost certainly that your data is part of the model. For a firm whose competitive advantage is the depth of its detail library and the institutional knowledge embedded in past projects, this is a quiet but real form of leaking IP.
The second question is about whether the tool was built for a specific job. AI products being sold to firms today are general-purpose: a chat box, a writing assistant, a "creative copilot." They're handed to engineers with the expectation that the engineer will figure out how to make them useful. That's not a tool, that's a research project. The firms that get real value from AI are the ones that pick narrow, expensive workflows and find tools that complete them end-to-end without making the employee learn a new way to work. The difference between a successful AI rollout and a failed one is rarely the model's capability. It's almost always whether the tool was designed for a specific job an engineer already does every day, or whether it expects the engineer to invent the workflow themselves. Asking a 50-engineer firm to "figure out how to use AI" produces 50 different experiments, 50 different outcomes, and zero institutional learning. Asking that same firm to adopt a tool that automates one specific workflow produces a measurable result by Friday.
These two questions are the lens we used when building Details. On the data side, every Recs query is routed through Vertex AI under our own Google Cloud project, authenticated with IAM rather than an API key, and Google's enterprise data-governance commitment for Vertex applies: no firm data is used to train the underlying models, no firm data is shared outside the project, and no human at Google reads it as part of standard operation. We don't hold long-term copies of the request content on our side either. The detail metadata that gets sent to the model exists for the duration of the request and nothing more. The firms using Details know exactly where their information goes and what happens to it after, which is the only acceptable answer for a tool that touches project work.
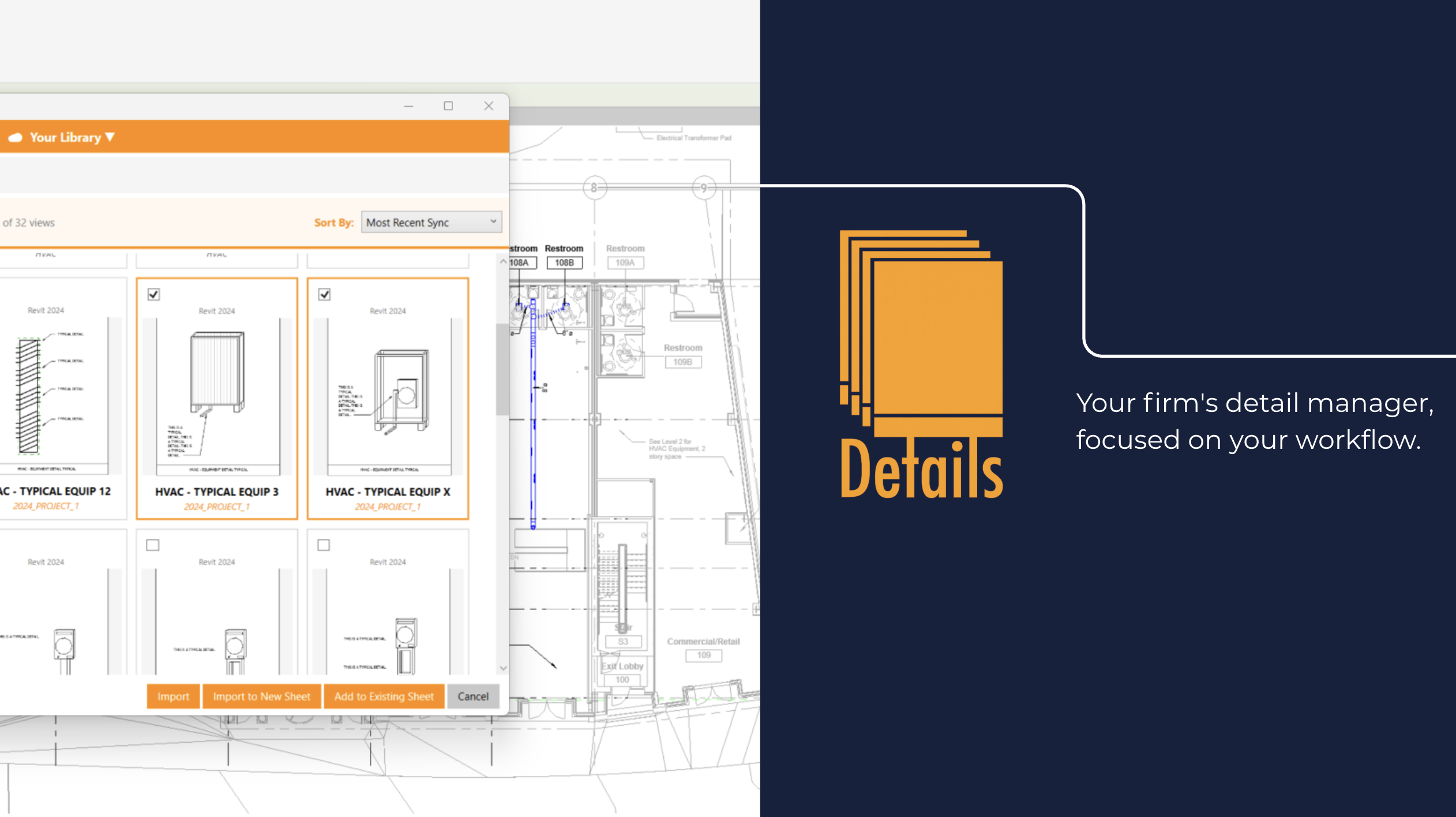
On the use-case side, Details doesn't ask engineers to figure anything out. The tool was built for one specific job: managing and applying the firm's detail library inside Revit. Recs, the AI engine inside Details, watches the active model and surfaces the firm's most relevant details automatically based on the system being designed, the equipment that's been placed, and the patterns of past work. There's no chat box, no prompt engineering, no learning curve. The engineer opens the panel and the right details are at the top. The other half of the workflow, dropping selected details onto sheets in a clean, template-compliant grid, finishes in one click. AI is doing real work in both halves, but the engineer never has to think about it. They see results, not a model.
This is what AI usage in an MEP firm should look like in 2026. The firms that get it right will be the ones that refuse to deploy tools that train on their work and refuse to deploy tools that don't know what job they're doing. The ones that get it wrong will spend the next two years subsidizing model training with their project archive while their engineers try to invent workflows that the tool never actually delivered. The two questions are simple. The downside of skipping them is large.